Introducción a OpenSearch
Instalación de servidor
Primero configuraremos el usuario que va a ejecutar las aplicaciones, en este caso opensearch:
useradd -m opensearch
su opensearch
bash
Por simplicidad vamos a correr las aplicaciones desde el home del usuario opensearch.
La instalación no da problemas y se hace muy rápido siguiendo la guía: https://opensearch.org/docs/opensearch/install/tar/
tar -zxf opensearch-1.0.1-linux-x64.tar.gz
cd opensearch-1.0.1
Antes de poder ejecutarlo es necesario hacer ciertos cambios en la configuración de opensearch (opensearch-1.0.1/config/opensearch.yml):
Le daremos un nombre al nodo, haremos que sea accesible desde fuera y configuraremos el descubrimiento de nodos:
node.name: OpenSearch1
network.host: 0.0.0.0
discovery.seed_hosts: ["127.0.0.1"]
Finalmente vamos a añadir una línea muy importante y sin la cual no podremos indexar logs con las últimas versiones de filebeat:
compatibility.override_main_response_version: true
Este parámetro engaña al agente haciendole creer que están en la misma versión.
En este punto ya tenemos OpenSearch funcionando, pero nos falta la interfaz gráfica.
Igualmente solo hay que seguir la guía: https://opensearch.org/docs/dashboards/install/tar/
tar -zxf opensearch-dashboards-1.0.1-linux-x64.tar.gz
cd opensearch-dashboards
Editaremos de igual modo el archivo de configuración (opensearch-dashboards-1.0.1/config/opensearch_dashboards.yml):
server.host: "0.0.0.0" # No viene por defecto
opensearch.hosts: ["https://localhost:9200"]
opensearch.ssl.verificationMode: none
opensearch.username: "kibanaserver"
opensearch.password: "kibanaserver"
Y finalmente crearemos los servicios de Systemd para poder ejecutarlos como servicio:
/etc/systemd/system/opensearch.service
[Unit]
Description=OpenSearch server
After=network.target
[Service]
ExecStart=/home/opensearch/opensearch-1.0.1/opensearch-tar-install.sh
User=opensearch
[Install]
WantedBy=multi-user.target
/etc/systemd/system/dashboard.service
[Unit]
Description=OpenSearch Dashboard server
After=network.target
[Service]
ExecStart=/home/opensearch/opensearch-1.0.1/opensearch-dashboards-1.0.1/bin/opensearch-dashboards
User=opensearch
[Install]
WantedBy=multi-user.target
Ya podemos habilitar y lanzar las aplicaciones:
systemctl enable opensearch
systemctl start opensearch
systemctl enable dashboard
systemctl start dashboard
Podemos acceder a la interfaz gráfica (antes conocida como Kibana) desde http://10.10.10.52:5601, credenciales admin:admin:
Nos saldrá un mensaje para seleccionar un “tenant”, que no es otra cosa que espacios de trabajo para compartir busquedas, notebooks, indices… pudiendo cambiar en cualquier momento de tenant desde la barra superior. Más información sobre tenants
En este punto sería interesante cambiar la contraseña del usuario admin. Normalmente los cambios de contraseña se hacen desde el plugin “Security”, no obstante para cambiar la contraseña del usuario admin interno se debe hacer con herramientas externas:
JAVA_HOME=/home/opensearch/opensearch-1.0.1/jdk/ ./opensearch-1.0.1/plugins/opensearch-security/tools/hash.sh
[Password:]
$2y$12$e0AKPtCgVzL5iPZe/tybm.sIyLS5YmdY9dydmtFOp7/E4z7VtbJQK
Y en opensearch-1.0.1/plugins/opensearch-security/securityconfig/internal_users.yml cambiamos el valor del parámetro hash del usuario admin por $2y$12$e0AKPtCgVzL5iPZe/tybm.sIyLS5YmdY9dydmtFOp7/E4z7VtbJQK
Nota: hacer lo mismo para el usuario kibanaserver acordándonos de cambiar en el archivo de configuración del dashboard las credenciales.
Nota2: cualquier configuración ya realizada en OpenSearch se perderá.
Aunque estos cambios no serán efectivos, para ello tendremos que usar la tool securityadmin.sh:
opensearch@OpenSearch:~$ JAVA_HOME=/home/opensearch/opensearch-1.0.1/jdk/ ./opensearch-1.0.1/plugins/opensearch-security/tools/securityadmin.sh -cacert ./opensearch-1.0.1/config/root-ca.pem -cert ./opensearch-1.0.1/config/kirk.pem -key ./opensearch-1.0.1/config/kirk-key.pem -cd ../securityconfig/ -w
Security Admin v7
Will connect to localhost:9300 ... done
Connected as CN=kirk,OU=client,O=client,L=test,C=de
OpenSearch Version: 1.0.0
OpenSearch Security Version: 1.0.1.0
{
"whoami" : {
"dn" : "CN=kirk,OU=client,O=client,L=test,C=de",
"is_admin" : true,
"is_authenticated" : true,
"is_node_certificate_request" : false
}
}
opensearch@OpenSearch:~$ JAVA_HOME=/home/opensearch/opensearch-1.0.1/jdk/ ./opensearch-1.0.1/plugins/opensearch-security/tools/securityadmin.sh -cacert ./opensearch-1.0.1/config/root-ca.pem -cert ./opensearch-1.0.1/config/kirk.pem -key ./opensearch-1.0.1/config/kirk-key.pem -cd ./opensearch-1.0.1/plugins/opensearch-security/securityconfig/ -icl -nhnv
Security Admin v7
Will connect to localhost:9300 ... done
Connected as CN=kirk,OU=client,O=client,L=test,C=de
OpenSearch Version: 1.0.0
OpenSearch Security Version: 1.0.1.0
Contacting opensearch cluster 'opensearch' and wait for YELLOW clusterstate ...
Clustername: opensearch
Clusterstate: YELLOW
Number of nodes: 1
Number of data nodes: 1
.opendistro_security index already exists, so we do not need to create one.
Populate config from /home/opensearch/opensearch-1.0.1/plugins/opensearch-security/securityconfig
Will update '_doc/config' with ./opensearch-1.0.1/plugins/opensearch-security/securityconfig/config.yml
SUCC: Configuration for 'config' created or updated
Will update '_doc/roles' with ./opensearch-1.0.1/plugins/opensearch-security/securityconfig/roles.yml
SUCC: Configuration for 'roles' created or updated
Will update '_doc/rolesmapping' with ./opensearch-1.0.1/plugins/opensearch-security/securityconfig/roles_mapping.yml
SUCC: Configuration for 'rolesmapping' created or updated
Will update '_doc/internalusers' with ./opensearch-1.0.1/plugins/opensearch-security/securityconfig/internal_users.yml
SUCC: Configuration for 'internalusers' created or updated
Will update '_doc/actiongroups' with ./opensearch-1.0.1/plugins/opensearch-security/securityconfig/action_groups.yml
SUCC: Configuration for 'actiongroups' created or updated
Will update '_doc/tenants' with ./opensearch-1.0.1/plugins/opensearch-security/securityconfig/tenants.yml
SUCC: Configuration for 'tenants' created or updated
Will update '_doc/nodesdn' with ./opensearch-1.0.1/plugins/opensearch-security/securityconfig/nodes_dn.yml
SUCC: Configuration for 'nodesdn' created or updated
Will update '_doc/whitelist' with ./opensearch-1.0.1/plugins/opensearch-security/securityconfig/whitelist.yml
SUCC: Configuration for 'whitelist' created or updated
Will update '_doc/audit' with ./opensearch-1.0.1/plugins/opensearch-security/securityconfig/audit.yml
SUCC: Configuration for 'audit' created or updated
Done with success
Como veis este servidor de OpenSearch tiene configuraciones, certificados, usuarios ya precargados que habrá que limpiar si queremos llevarlo a producción.
Agente filebeat
Instalación
En mi caso ya dispongo de un servidor ejecutando el proxy Squid, por lo que lo que haremos será instalarle el agente de Filebeat para que nos mande los logs ya parseados al servidor de OpenSearch.
Los recomendados por opensearch son: En nuestro caso vamos a elegir filebeat. Será la version OSS 7.12.1. A la vez descargaremos la última versión de FIlebeat ya que trae el módulo de Squid cargado:v7.14.2
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-oss-7.12.1-amd64.deb
dpkg -i filebeat-oss-7.12.1-amd64.deb
# Instalación de módulo de Squid
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.14.2-linux-x86_64.tar.gz
tar -xf filebeat-7.14.2-linux-x86_64.tar.gz
cd filebeat-7.14.2-linux-x86_64/
cp modules.d/squid.yml.disabled /etc/filebeat/modules.d/squid.yml
cp module/squid /usr/share/filebeat/module/
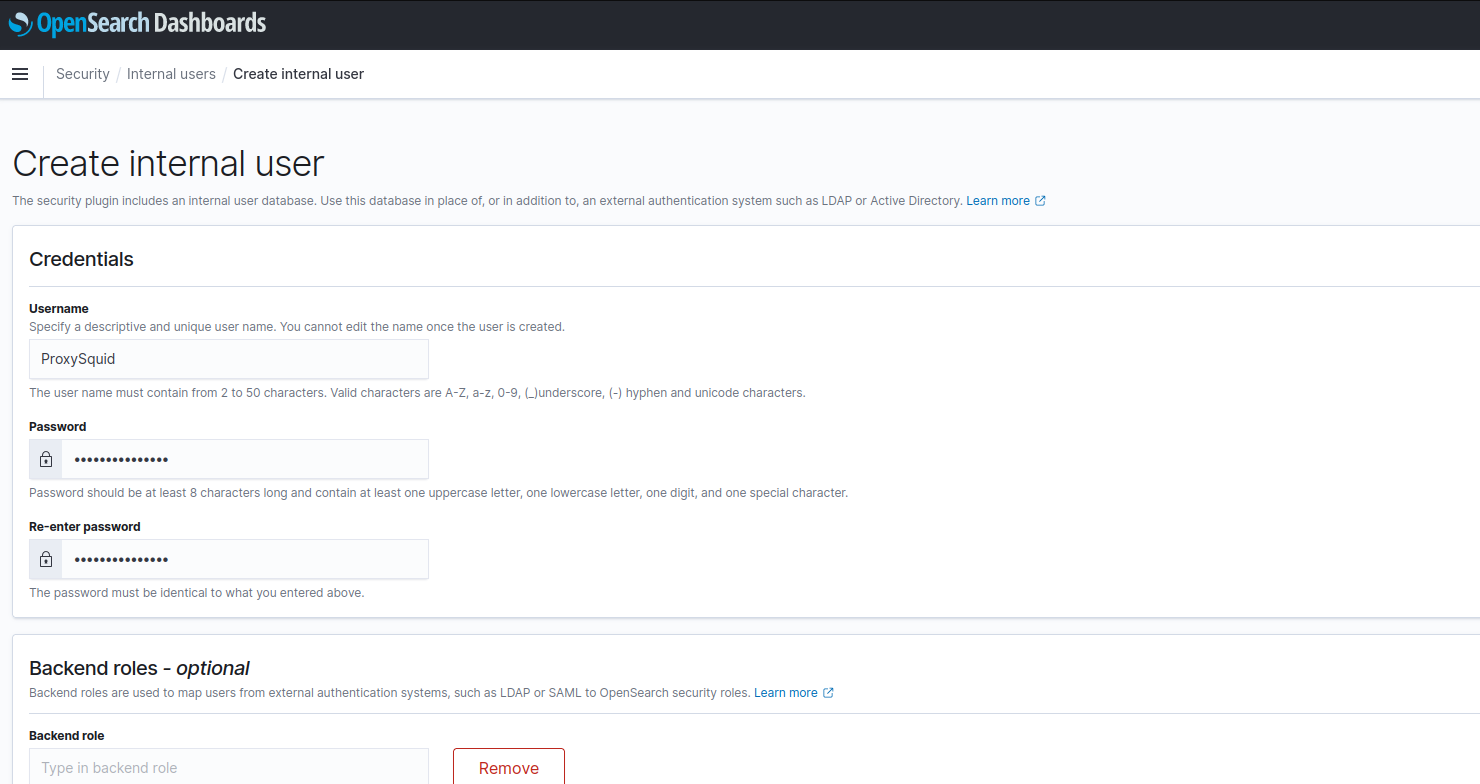
Usuario y rol de envío de logs
Y el rol necesario que llamaremos bulk_access:
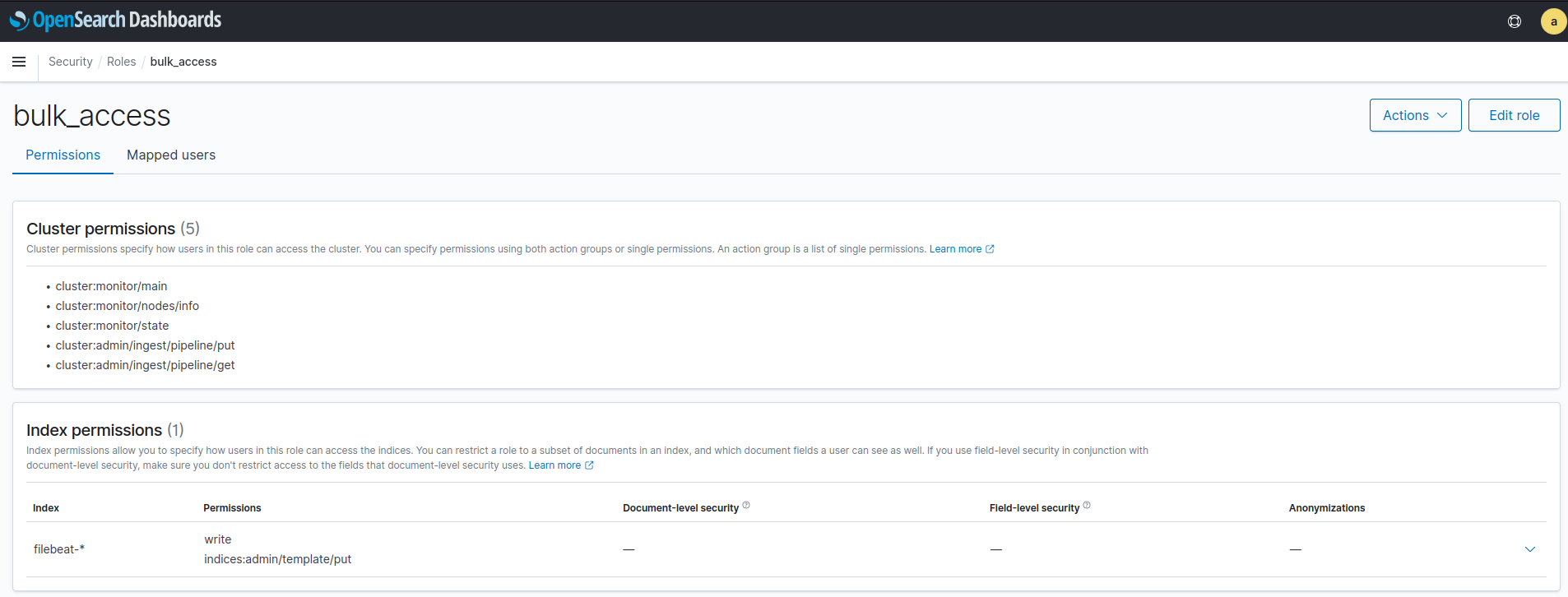
Los permisos a nivel de cluster necesarios son:
- cluster:monitor/main
- cluster:monitor/nodes/info
- cluster:monitor/state
- cluster:admin/ingest/pipeline/put
- cluster:admin/ingest/pipeline/get
Y a nivel de indice filebeat-*
- write
- indices:admin/template/put
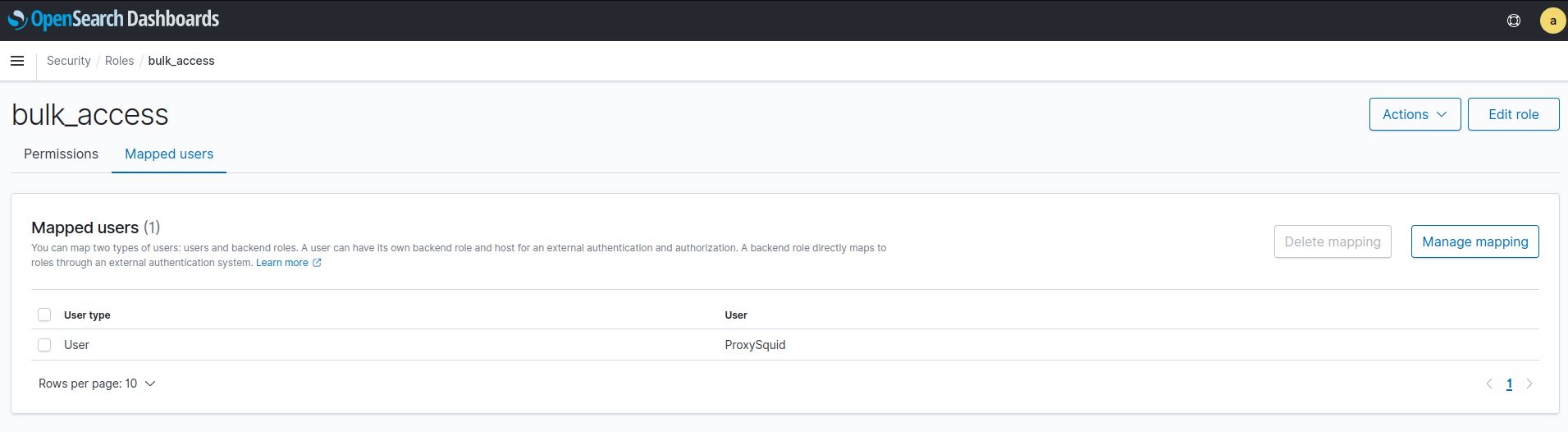
También es necesario darle este rol al usuario ProxySquid desde el panel *Mapped users**:
Configuración de Filebeat
Editamos la configuración de filebeat (/etc/filebeat/filebeat.yml):
hosts: ["https://10.20.0.252:9200"]
protocol: "https"
username: "ProxySquid"
password: "xxxxxxxxxxxxxxxxx"
ssl:
verification_mode: none
Configuraremos el módulo squid (/etc/filebeat/modules.d/squid.yml) para que lea de archivo:
- module: squid
log:
enabled: true
# Set which input to use between udp (default), tcp or file.
var.input: file
# var.syslog_host: localhost
# var.syslog_port: 9520
# Set paths for the log files when file input is used.
var.paths:
- "/var/log/squid/access.log"
- "/var/log/squid/cache.log"
Tras esto ya podemos arrancar el servicio filebeat:
systemctl enable filebeat
systemctl start filebeat
Y estaremos recibiendo nuestros logs en OpenSearch
Y si no hay logs, siempre podemos forzarlos haciendo una petición al proxy con:
curl --proxy 10.20.0.253:3128 google.com
Explorando OpenSearch
Query Workbench
Creo que una imagen vale más que mil palabras:
select @timestamp, source.ip, destination.ip, url.original FROM filebeat-* WHERE observer.product = 'Proxy' AND log.file.path = '/var/log/squid/access.log' ORDER BY @timestamp DESC LIMIT 50;
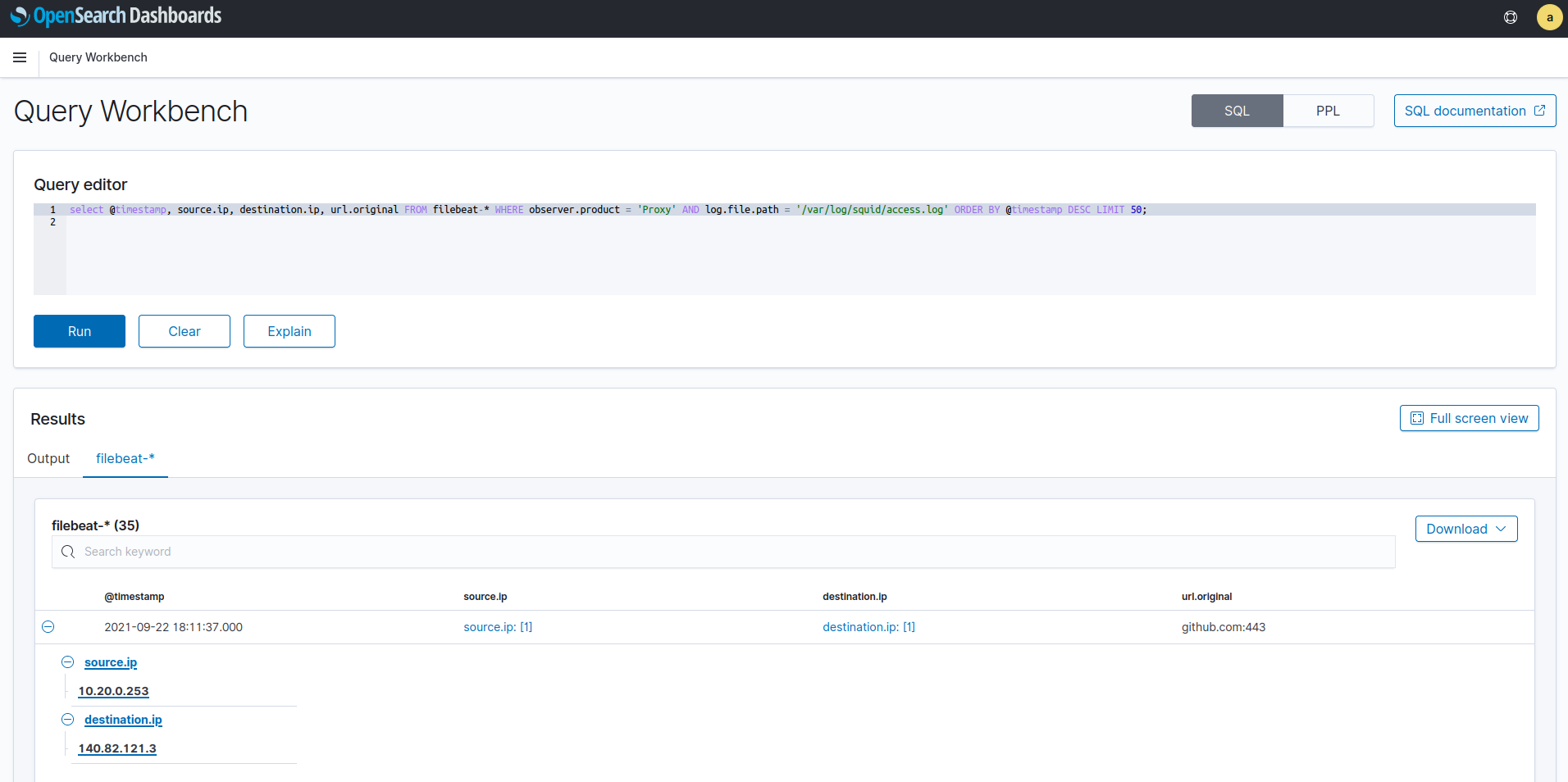 Este sería el uso con sintaxis SQL, pero tenemos la alternativa PPL que si hemos trabajado con Splunk nos sonará el formato ya que emplea también pipes (“|”) para concatenar distintos procesados:
Este sería el uso con sintaxis SQL, pero tenemos la alternativa PPL que si hemos trabajado con Splunk nos sonará el formato ya que emplea también pipes (“|”) para concatenar distintos procesados:
search source=filebeat-* | fields `@timestamp`, `source.ip`, `destination.ip`, `url.original` | sort + @timestamp
Nota: La clausula where no he conseguido que funcione en PPL.
Alertas y monitores
El panel Alerting nos proporcina tres subpaneles:
- Dashboard: Ver las alertas que han saltado
- Monitors: Los monitores no son más que querys lanzadas a intervalos regulares de tiempo. Esta query define una ventana de tiempo (Ultimas X horas, minutos o segundos), una método de agregación (count, sum, min, max y avg) así como una condición de filtrado. Luego se establecen trigers en el propio monitor que definirán las condiciones exactas que harán saltar una alerta así como definir las acciones (notificaciones) a realizar. Se pueden definir varios trigers por monitor.
- Destinations: Gestionar a quien notificar: Web hooks, Slack, Email…
Por ejemplo una regla que detecta cuando hay más de 10 peticiones a github:
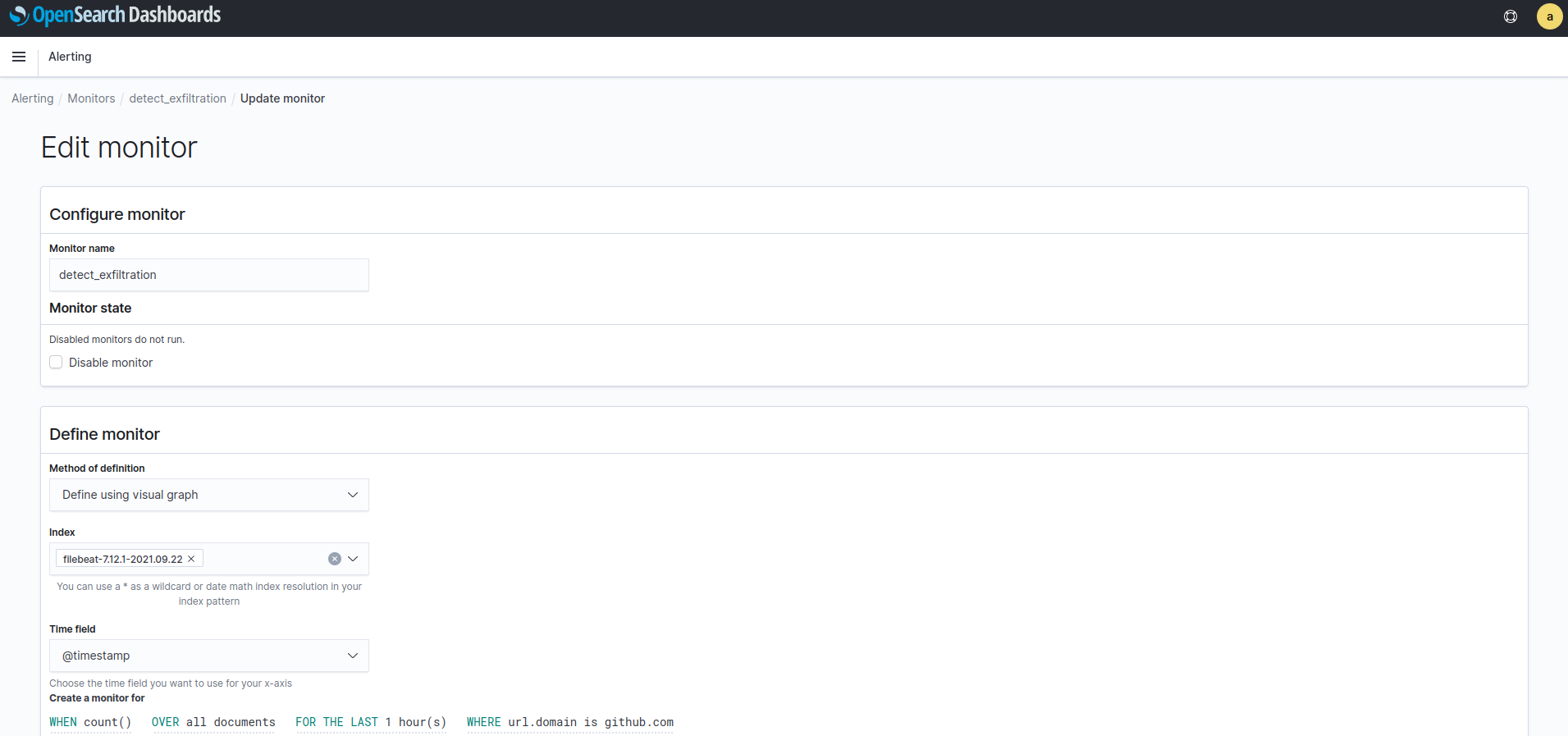
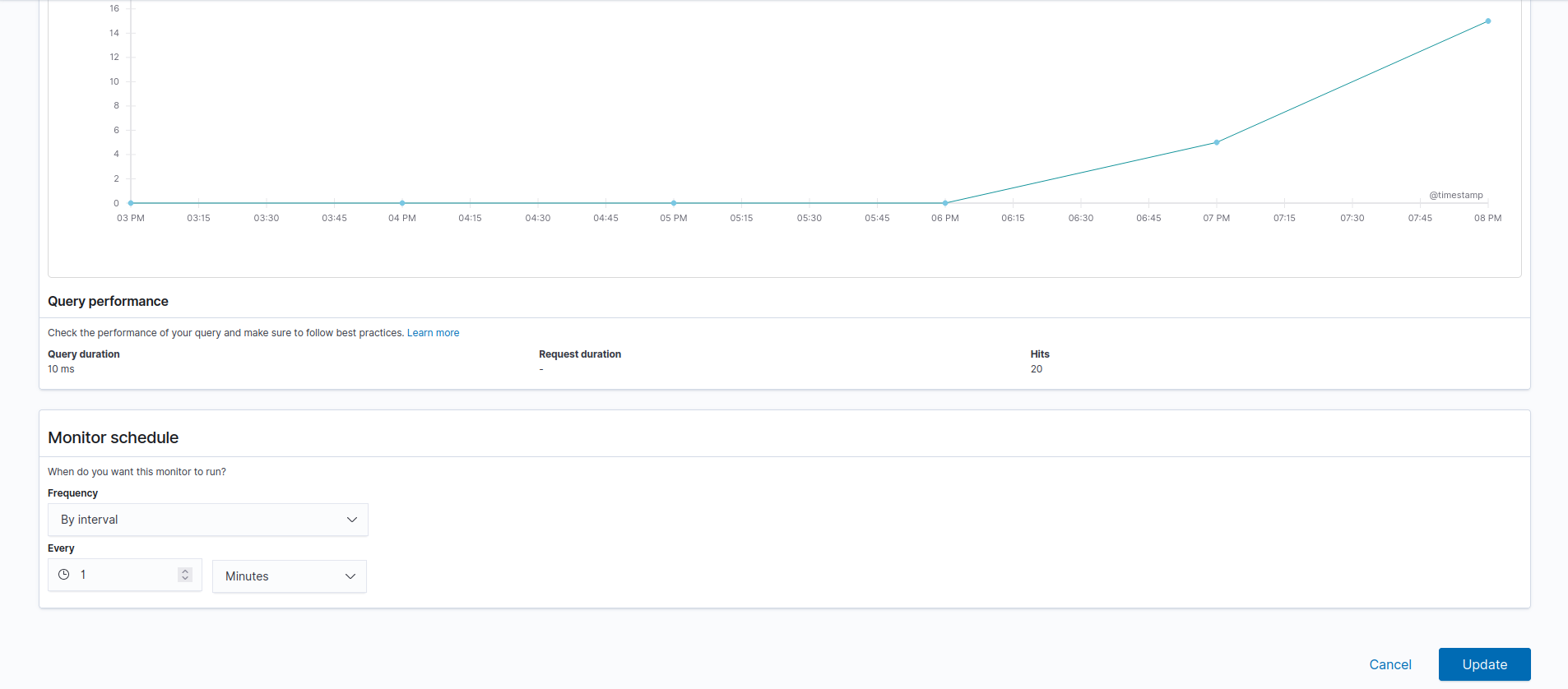
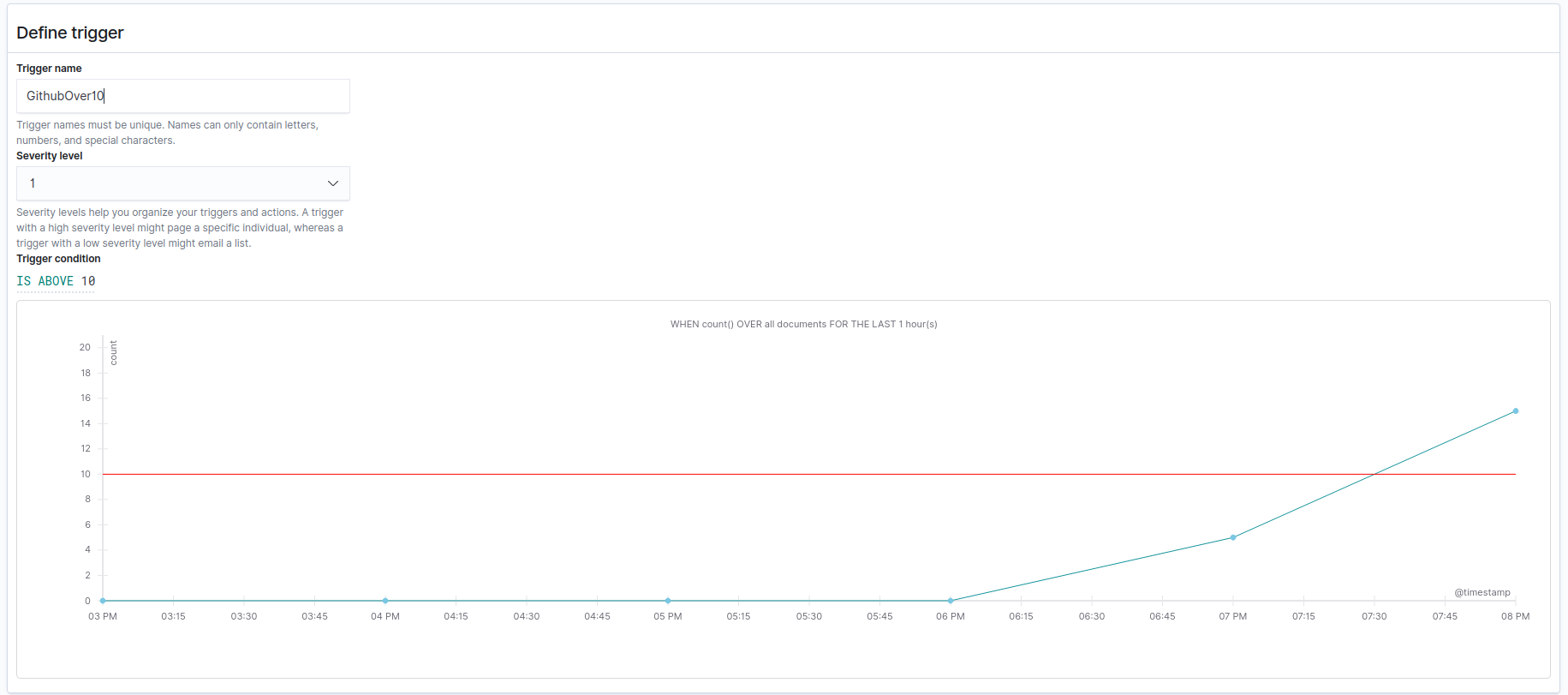
Podemos hacer que salte la regla con:
for i in {1..10}; do curl --proxy 10.20.0.253:3128 https://github.com/; done
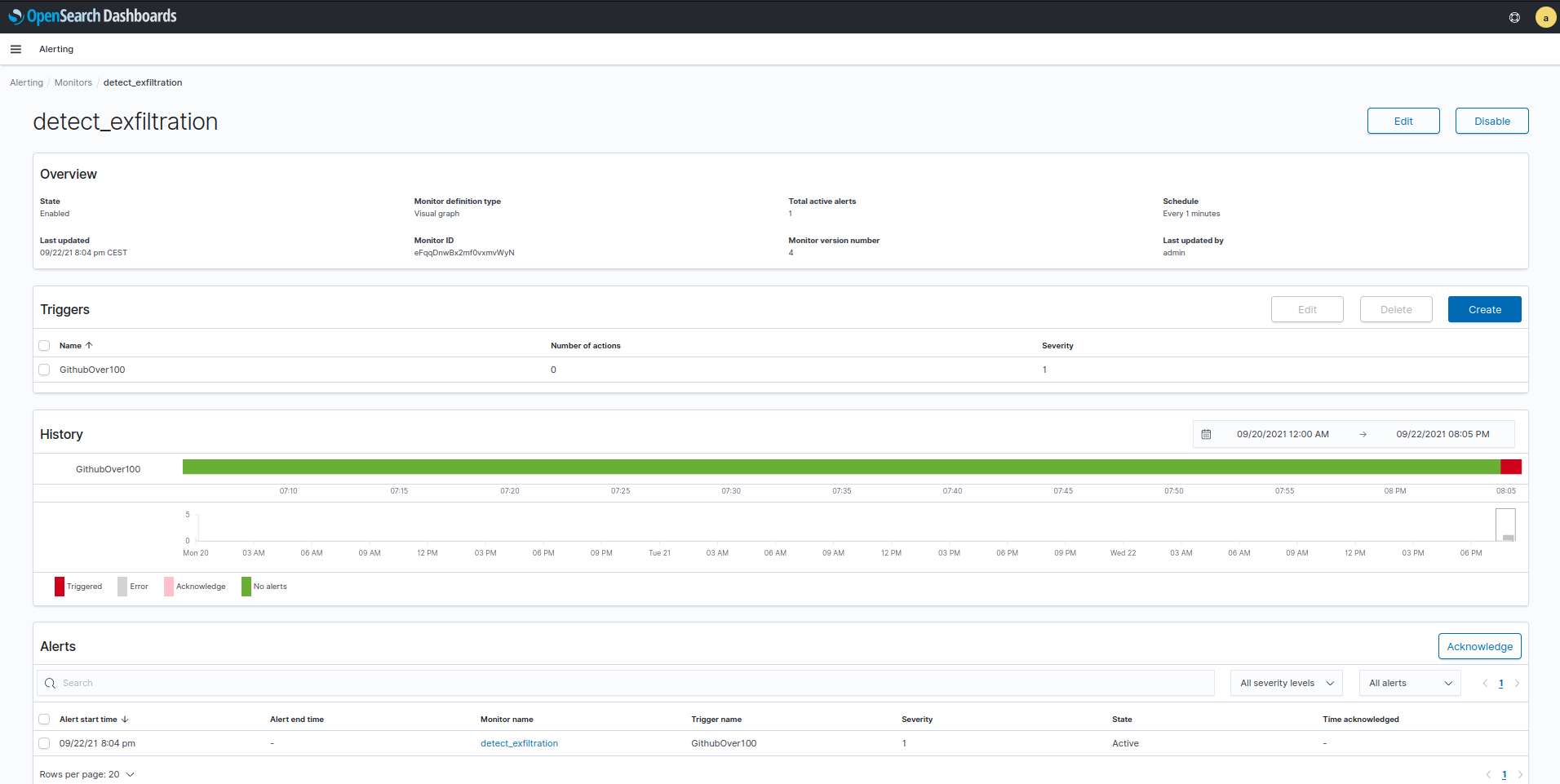
Obviamente esta regla no sirve de mucho pero nos podemos hacer una idea de las posibilidades.
Hay más opciones como utilizar umbrales teniendo en cuenta detectores de anomalías o incluso ejecución de scripts:
// Performs some crude custom scoring and returns true if that score exceeds a certain value
int score = 0;
for (int i = 0; i < ctx.results[0].hits.hits.length; i++) {
// Weighs 500 errors 10 times as heavily as 503 errors
if (ctx.results[0].hits.hits[i]._source.http_status_code == "500") {
score += 10;
} else if (ctx.results[0].hits.hits[i]._source.http_status_code == "503") {
score += 1;
}
}
if (score > 99) {
return true;
} else {
return false;
}
Detección de anomalias
Este apartado es ligeramente distinto aunque en el fondo es crear reglas para detectar anomalías. La anomalía no es otra cosa que una desviación de los rangos (equivalente a el umbral establecido en un monitor) que calcula dinámicamente un algoritmo de Machine Learning.
Y la verdad que es muy sencillo de trabajar. Cuando creamos un Detector establecemos unas condiciones de filtrado así como una ventana de tiempo. Tras este paso se establecen las features o características que alimentaran a nuestro modelo de ML.
El parámetro window delay como su nombre indica hace que la query se realice a distinto intervalo de tiempo ya que por ejemplo una periodicidad de 30 minutos siempre hará las querys a y 30 minutos o a en punto y si tardamos por ejemplo 10 minutos en procesar los logs antes de indexarlos en OpenSearch y que estén disponibles a los usuarios estaremos perdiendo un tercio de los logs. Más sobre detección de anomalías
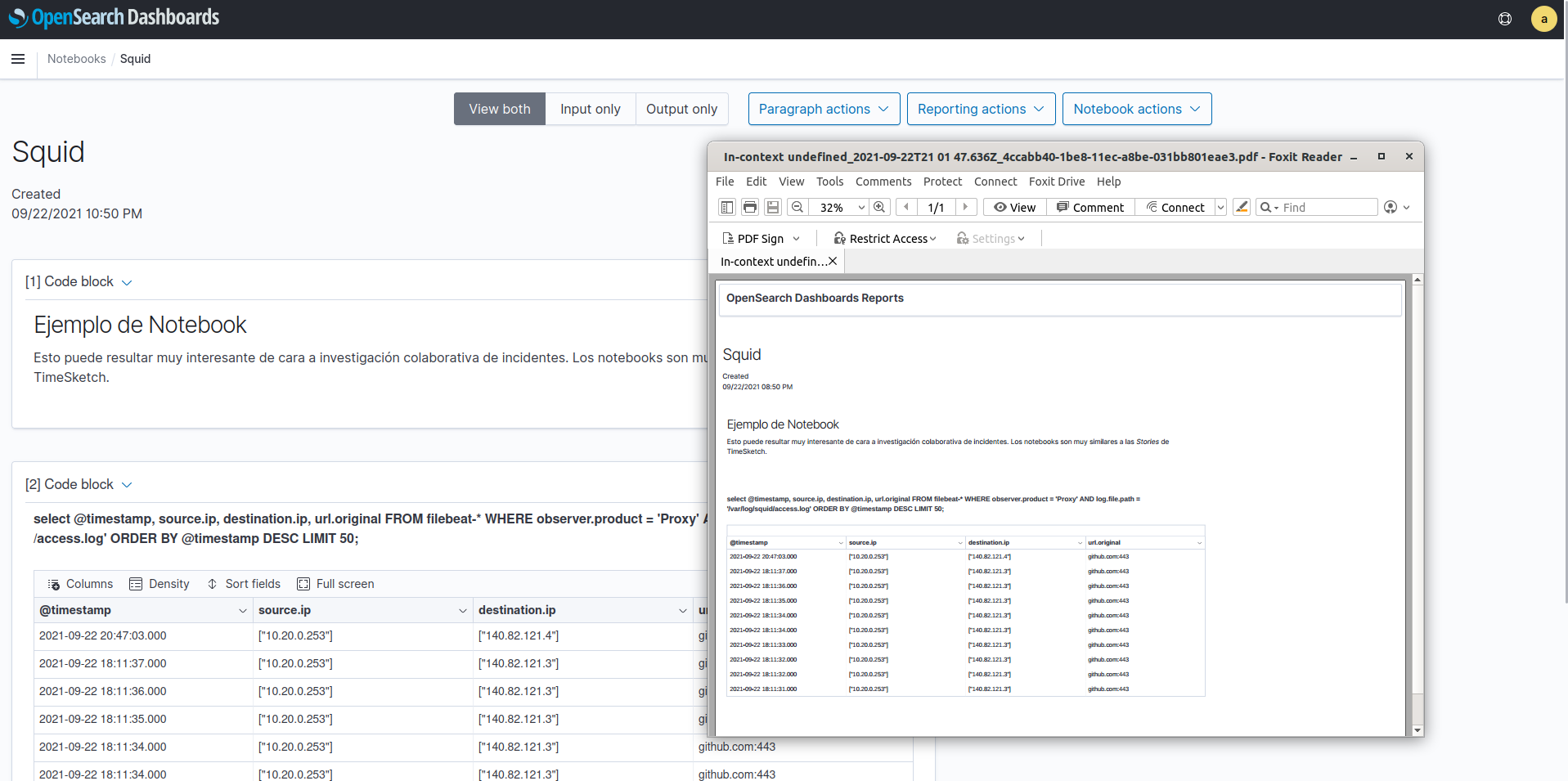
Notebooks
Básicamente un notebook nos va a permitir mantener de forma colaborativa un informe de un incidente pudiendo añadir los resultados de querys así como gráficos. Es muy similar a las stories de TimeSketch, aunque en este caso tendremos que controlar el tiempo absoluto de las querys ya que continuamente se están ingestando nuevos logs en el sistema.
Las notas a añadir son tres:
- Notas de texto en markdown
- Resultado de búsqueda SQL
- Resultado de búsqueda ppl
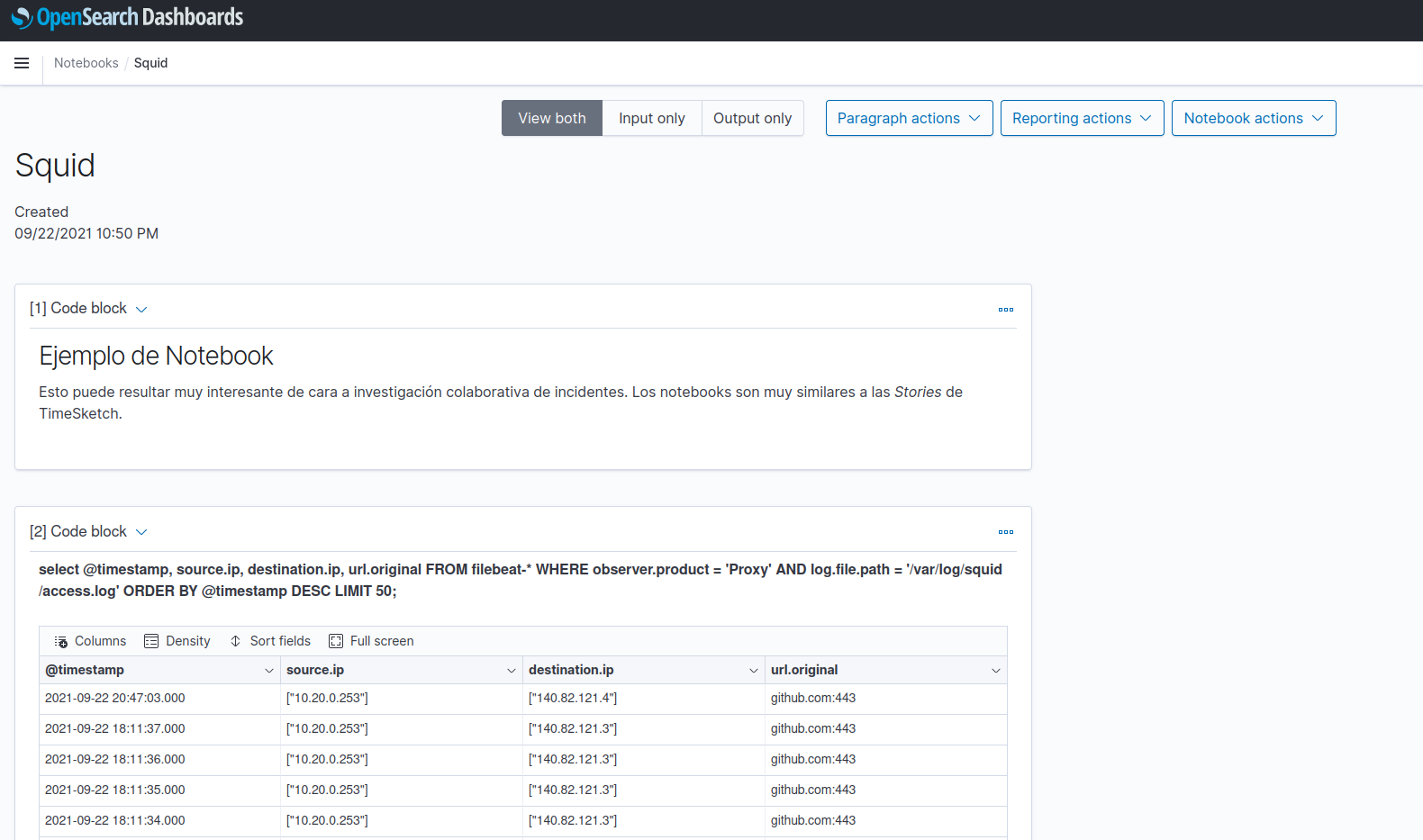
Una vez rellenado el notebook podemos exportarlo en formato PNG o PDF. Para que la exportación funcione es necesario tener las siguientes dependencias:
sudo apt install -y libnss3-dev fonts-liberation libfontconfig1